
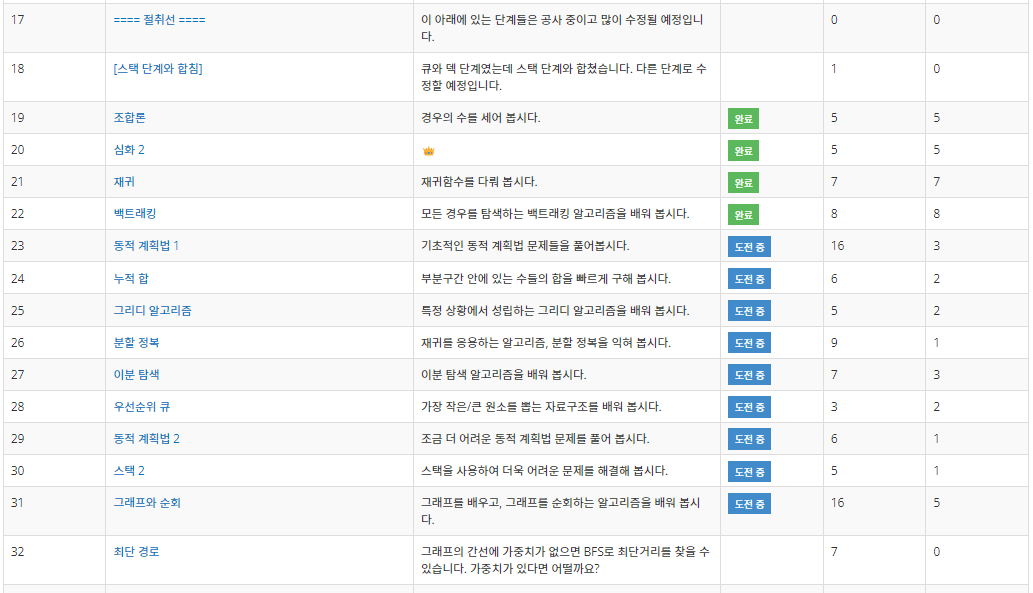
목차 |
그래프와 트리 탐색 알고리즘
|
|
| 백트래킹의 소개 개발 활용 사례(예산 활용법 찾기) 백준 문제 |
α–β A* B* 퇴각검색 빔 벨먼-포드 최상 우선 양방향 Borůvka 분기 한정법 BFS 영국박물관 D* DFS |
데이크스트라 에드먼즈 플로이드-워셜 Fringe search 언덕등반기법 IDA* 반복적 깊이심화 존슨 Jump point 크러스컬 Lexicographic BFS LPA* 프림 SMA* |
| 출처: https://ko.wikipedia.org/wiki/%ED%87%B4%EA%B0%81%EA%B2%80%EC%83%89 | ||
퇴각검색 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 퇴각검색(영어: backtracking, 한국어: 백트래킹)은 한정 조건을 가진 문제를 풀려는 전략이다. "퇴각검색(backtrack)"이란 용어는 1950년대의 미국 수학자 D. H. 레머가
ko.wikipedia.org
백트래킹
백트래킹은 제약 충족 문제에서 해를 찾기 위해 사용되는 알고리즘이다. 가능한 모든 조합을 시도해보면서 문제의 해답을 찾는 방식으로, 깊이 우선 탐색(DFS)의 일종이라고 볼 수 있다. 탐색 중 조건 불만족 시 이전 단계로 돌아가(Backtrack) 다른 경로를 탐색하는 전략을 사용한다.
- 개념
해결책 후보를 구축하다가, 조건을 만족하지 않을 것이라 판단되면, 즉시 버리고(즉, 더 이상의 자식 노드 탐색을 중지하고) 마지막으로 성공적이었던 노드 상태로 돌아가 다른 가능성을 탐색한다. 이 방법은 브루트 포스 방법의 일종이지만, 모든 가능성을 탐색하는 대신 실패가 예상되는 경로는 조기에 포기해 탐색 효율을 높인다.
- 구현 방법
백트래킹 알고리즘의 구현은 재귀 함수를 이용하는 것이 일반적이다. 각 재귀 호출은 선택지 중 하나를 선택하고, 선택이 유망한지를 검사한다. 유망하지 않다고 판단되면, 해당 경로를 포기하고(백트랙), 이전 상태로 되돌아간 후 다른 선택지를 탐색한다. 구현의 핵심 단계는 다음과 같다.
- 선택: 현재 상태에서 가능한 선택지 중 하나를 선택한다.
- 제약 조건 검사: 선택이 문제의 제약 조건을 만족하는지 검사한다.
- 목표 도달 검사: 현재 상태가 문제의 해답인지 검사한다.
- 재귀 호출: 유망하다면 다음 상태로 진행한다. 그렇지 않다면 다른 선택지를 탐색한다.
- 성능 개선 방법
본 백트래킹의 성능을 개선하는 방법은 주로 탐색 공간을 줄이는 데 초점을 맞춘다. 이를 위한 몇 가지 방법은 다음과 같다.
- 유망성 검사(Promising Check): 불필요한 경로를 조기에 차단하여 탐색 공간을 줄인다.
- 가지치기(Pruning): 해가 될 가능성이 없는 경우 그 경로의 탐색을 중단한다.
- 동적 계획법(Dynamic Programming) 사용: 이미 계산된 결과를 저장하여 중복 계산을 방지한다.
- 휴리스틱 사용: 문제의 특성을 고려한 휴리스틱을 사용하여 더 유망한 후보를 우선적으로 탐색한다.
백트래킹은 N-Queen 문제, 해밀턴 경로 문제, 부분 집합의 합 문제 등 많은 문제에서 해를 찾는 데 유용하게 사용될 수 있다. 그러나 가능한 모든 경우의 수가 매우 많거나, 문제가 NP-완전 문제인 경우에는 백트래킹으로 해를 찾는 것이 실용적이지 않을 수 있다.
개발 활용 사례( 예산 활용법 찾기)
5년 전에 소프트 테니스 팀의 감독을 맡아서 전국 방방곡곡의 대회장 주변 마트에서 간식을 사면서, 1230원 따위로 가격이 정해진 바나나를 보고 스트레스를 받다가(사실 바보라서 몰랐지만 예산보다 넘치게 산 후 개인 카드로 분할 결제하면 된다.) 정해진 예산에 대해 여러 가격의 물건이 있을 때, 예산에 딱 맞아 떨어지게 물건을 구입하는 방법을 계산하는 프로그램을 만들고 싶었다. 여러 버전으로 만들면서 실력이 좀 늘었고 3번째 완성한 알고리즘에서는 그럭저럭 쓸만한 물건이 되었다.



하지만 조금만 예산이 커지거나 아이템의 수가 늘어나도 프로그램이 뻗었고, 이것을 해결하기 위해 떠올린 방법이 일종의 백트래킹이었다(는 것을 이제 알았다). 트리를 모르고 파이썬도 지금보다 잘 못하는 상태기 때문에 코드나 발상이 기이할 수 있다. (이 코드가 백트래킹이라는 것은 브루투포스에 비해 상대적으로 백트래킹 같다는 것이다. 사실 어떤 관점에서 이건 그냥 DFS다!)다음은 당시 작성한 코드의 각주다.
"""
Budget Simulator V4 Ver 0.97
Planed on MS EXCEL
Coded by Hyunsu Park(Hanzch), South Korea.
is Redcubes and Uranus 97.77Degs.
This is a program that attempts to solve the problem(finding the way
to spend all the budget with priced items.) that the last version
solved with a new approach.
Previous version checked the maximum number of every items. Huge number
of impossible cases(ex: max,max,max...) were tested. But we can not buy
the maximum amount for EVERY item. Because it is maximum for each item
in budget. But the program has checked that and found error.
And it also had to check all of the cases that lefts a lot of budget.
So this has resulted in a slower rate of operation. For example, V3
should checks 240 cases to solve in condition below.
(budget=24, 5 items, priced each 17,13,11,7,5)
This one uses nodes witch means currunt modifying position. The last
item's quantity is decided by money for anothers. So we don't have to
count up and check this out. Default node is item just before the last
item. The program counts up that node one by one. If it cannot raise
quantity in budget on current node, it Initializes the node's quantity
to 0 and moves node forward.And it adds upper-node's quantity one more.
After that it checks if error occurs(the Error means over budget, there
is no more way except changing other nodes) If there are errors,
initialize current to 0 and node up again. If there is no error, move
node to Default. Do this until first node occurs ERROR.
It can reduces the number of cases. For example, V4 should checks
23 cases to solve in same condition.
(budget=24, 5 items, priced each 17,13,11,7,5)
The logical steps of this program are shown in the table below.
_________________________________________________________________
################## PROGRAM'S LOGICAL PLAN ################
There are 5 items.
Budget = 24
_____COST_____| NODE INDEX RANGE: 0 ~ 4
17_13_11_7__5_| NODE DEFAULT = 3 ______________
___QUANTITY___|NO|________________ __LEFT MONEY__|__________
a__b__c__d__e_|DE|____BEHAVIOR____ |_a__b__c__d__e __SAVING__
0 0 0 0 4 | 3|Qnty+1&Node=(n-2)[24 24 24 24 4]Close-Save
0 0 0 1 3 | 3|Qnty+1&Node=(n-2)[24 24 24 17 2]Close-Save
0 0 0 2 2 | 3|Qnty+1&Node=(n-2)[24 24 24 10 0]Exact-SAVE
0 0 0 3 0 | 3|Qnty+1&Node=(n-2)[24 24 24 3 3]Close-Save
0 0 0 4 ER | 3|Qnty=0&Node-1 [24 24 24 ER ER]ERROR-pass
0 0 1 0 2 | 2|Qnty+1&Node=(n-2)[24 24 13 13 3]Close-Save
0 0 1 1 1 | 3|Qnty+1&Node=(n-2)[24 24 13 6 1]Close-Save
0 0 1 2 ER | 3|Qnty=0&Node-1 [24 24 13 ER ER]ERROR-pass
0 0 2 0 0 | 2|Qnty+1&Node=(n-2)[24 24 2 2 2]Close-Save
0 0 2 1 ER | 3|Qnty=0&Node-1 [24 24 2 ER ER]ERROR-pass
0 0 3 0 ER | 2|Qnty=0&Node-1 [24 24 ER ER ER]ERROR-pass
0 1 0 0 2 | 1|Qnty+1&Node=(n-2)[24 11 11 11 1]Close-Save
0 1 0 1 0 | 3|Qnty+1&Node=(n-2)[24 11 11 4 4]Close-Save
0 1 0 2 ER | 3|Qnty=0&Node-1 [24 11 11 ER ER]ERROR-pass
0 1 1 0 0 | 2|Qnty+1&Node=(n-2)[24 11 0 0 0]Exact-SAVE
0 1 2 0 ER | 3|Qnty=0&Node-1 [24 11 ER ER ER]ERROR-pass
0 2 0 0 ER | 2|Qnty=0&Node-1 [24 ER ER ER ER]ERROR-pass
1 0 0 0 1 | 1|Qnty+1&Node=(n-2)[ 7 7 7 7 2]Close-Save
1 0 0 1 0 | 3|Qnty+1&Node=(n-2)[ 7 7 7 0 0]Exact-SAVE
1 0 0 2 ER | 3|Qnty=0&Node-1 [ 7 7 7 ER ER]ERROR-pass
1 0 1 0 ER | 2|Qnty=0&Node-1 [ 7 7 ER ER ER]ERROR-pass
1 1 0 0 ER | 1|Qnty=0&Node-1 [ 7 ER ER ER ER]ERROR-pass
2 0 0 0 ER | 0 EndLoop0NodeError[ER ER ER ER ER]ERROR-pass
"""영어권 앱으로 개발하고 공유해서 각주가 말도 안 되는 영어로 되어 있어 (해석)을 붙인다.
- 이 프로그램은 이전 버전이 해결했던 문제(예산을 모두 사용하여 일정 항목을 구매하는 방법 찾기)를 새로운 접근 방식으로 해결하려고 시도합니다. 이전 버전은 모든 항목의 최대 구매 가능 수량을 확인했습니다. 그래서 많은 불가능한 경우(예: 최대, 최대, 최대...)가 테스트되었습니다. 예산 내에서 각 항목의 최대 수량을 구매할 수는 없습니다. 왜냐하면 그것은 예산 내에서 한 항목만 살 경우의 최대구입 가능 수량이기 때문입니다. 하지만 프로그램은 그것을 확인하고 오류를 체크하느라 시간을 낭비했습니다. 또한 많은 예산이 남는 모든 경우 또한 확인해야 했으며, 이로 인해 작동 속도가 느려졌습니다. 예를 들어, V3는 다음 조건에서 문제를 해결하기 위해 240개의 경우를 확인해야 했습니다.
- (예산=24, 항목 5개, 각각 가격 17, 13, 11, 7, 5)
- 이 버전은 현재 수정 중인 위치를 의미하는 노드를 사용합니다. 마지막 항목의 수량은 다른 항목에 대한 돈에 의해 결정됩니다. 그래서 우리는 이를 계산하고 확인할 필요가 없습니다. 기본 노드는 마지막 항목 바로 앞의 항목입니다. 프로그램은 해당 노드의 수량을 하나씩 증가시킵니다. 현재 노드에서 예산 내에서 수량을 늘릴 수 없는 경우, 노드의 수량을 0으로 초기화하고 노드를 앞으로 이동합니다. 그리고 상위 노드의 수량을 하나 더 추가합니다. 그 후에 오류가 발생하는지 확인합니다(오류는 예산 초과, 다른 노드를 변경하는 것 외에 다른 방법이 없음을 의미합니다). 오류가 발생하면 현재를 0으로 초기화하고 다시 노드를 올립니다. 오류가 없으면 노드를 기본값으로 이동합니다. 첫 번째 노드에서 오류가 발생할 때까지 이 작업을 반복합니다. 이 방법은 사례의 수를 줄일 수 있습니다. 예를 들어, V4는 아래 조건에서 해결하기 위해 23개의 경우만 확인하면 됩니다. (예산=24, 항목 5개, 각각 가격 17, 13, 11, 7, 5)
- 이 프로그램의 논리적 단계는 아래 표에 나타나 있습니다.
- 코드 보기
10만원의 예산에 맞게 책을 고르는 모든 방법을 찾는 문제다.
budget = 100000
item = ["Clean Code", "진짜 챗GPT", "OpenCV 4로", "리액트 with","모두의 깃","실전! 텐서플로 2","비전공자도 이해하는 AI","진짜 챗GPT API","opencv-python으로 배우는","컴퓨터비전과 딥러닝","HTML + CSS + 자바","허스키렌즈"]
cost = [26400, 14400, 29400, 27000, 14000, 25200, 17820, 25200, 35000, 39000, 24300, 19000]
qnty = [0] * len(item) # Set the List to count the quantity of Each Items.
left = [0] * len(item) # Set the List to save left budget after spend (each item * quantity)
over = False # It checks budget over error.
leng = len(cost) # check the numbers of item to calculate.
node_end = leng - 2 # is the end of node we change quantity manually.
last_idx = leng - 1 # is the last number of list index
node = node_end # node number sets to node_end(default position)
case_number = 0 # counts how many cases we checked.
case_exact = [] # stores the case with no balance.
case_close = [] # stores the case with balance.
print ('__Generated_Data__')
# _____PRINT item list
print('_' * 46)
print('')
for n_prt in range(leng):
print('item #', format(n_prt + 1, '02d'), format(item[n_prt], '27s'), '$', format(cost[n_prt], '6,d'))
print('_' * 46)
"""QUICK SORT AND REVERSE This Quick sort code is a variation of the following site.
http://interactivepython.org/courselib/static/pythonds/SortSearch/TheQuickSort.html"""
def relQSort(cost, item):
index_end = len(cost) - 1
relQSortRecur(cost, 0, index_end)
def relQSortRecur(cost, first, last):
if first < last:
splitpoint = partition(cost, first, last)
relQSortRecur(cost, first, splitpoint - 1)
relQSortRecur(cost, splitpoint + 1, last)
def partition(cost, first, last):
pivot = cost[first]
marker_L = first + 1
marker_R = last
done = False
while not done:
while marker_L <= marker_R and cost[marker_L] >= pivot:
marker_L = marker_L + 1
while cost[marker_R] <= pivot and marker_R >= marker_L:
marker_R = marker_R - 1
if marker_R < marker_L:
done = True
else:
cost[marker_L], cost[marker_R] = cost[marker_R], cost[marker_L]
item[marker_L], item[marker_R] = item[marker_R], item[marker_L]
cost[first], cost[marker_R] = cost[marker_R], cost[first]
item[first], item[marker_R] = item[marker_R], item[first]
return marker_R
relQSort(cost, item) """sorted and reversed"""
print ('\n\n____Sorted_Data____')
# _____PRINT item list
print('_' * 46)
print('')
for n_prt in range(leng):
print('item #', format(n_prt + 1, '02d'), format(item[n_prt], '27s'), '$', format(cost[n_prt], '6,d'))
print('_' * 46)
# _____CORE
while not (node == -1 and over == True):
# CALCULATE THE BUDGET
# Set the left money after buy first item to left[0] according to list qnty[0]
left[0] = budget - (qnty[0] * cost[0])
# Set the left money after buy items to left[n] according to list qnty[n]
for n in range(1, last_idx):
left[n] = left[n - 1] - (qnty[n] * cost[n])
# With the left money, calculates How many items(Last one) can be bought.
qnty[last_idx] = int(left[last_idx - 1] / cost[last_idx])
left[last_idx] = left[last_idx - 1] - (qnty[last_idx] * cost[last_idx])
# CHECK ERROR(Over Purchasing)
# IF ERROR occurs reset current node's 'qnty'(quantity) to 0.
# and node up to count up upper node item's 'qnty'(quantity).
if any([i < 0 for i in left]):
over = True
qnty[node] = 0
node -= 1
# IF there is no ERROR, Set over to False.
# and reset node to the end(index of just before the last item in the list)
else:
over = False
node = node_end
# SAVE THE RESULT
# IF Balance is $0, then save it to the case_exact
# IF Balance is over $0, save it to the case_close
if (left[last_idx] == 0):
case_exact.append(list(qnty))
elif (left[last_idx] > 0):
case_close.append(list(qnty))
# PREPAIR NEXT CASE
qnty[node] += 1
case_number += 1
# _____Print result of the program.
if len(case_exact) == 0:
plural = 's'
isare = 'are'
if len(case_close) == 1:
plural = ''
isare = 'is'
# If there is no perfect case. set the close list to show.
print('There is no way to spend all of $',format(budget,'7,d'))
print('Next best case',plural,' ', isare, sep = '')
list_show = case_close
else:
# If there are perfect cases. set the exact list to show.
plural = 's'
if len(case_exact) == 1:
plural = ''
print('FOUND ', len(case_exact), ' PERFECT case', plural,' to spend $', format(budget,'7,d'), sep = '')
list_show = case_exact
# Print the title of List.
print(' ', end='')
for n_title in range(0, leng):
print('#', format(n_title + 1, '02d'), ' ', end='', sep='')
print('')
# List up cases.
for n_caseshow in list_show:
sum_show = 0
for n_index, n_itemshow in enumerate(n_caseshow):
sum_show += n_itemshow * cost[n_index]
print(format(n_itemshow, '3d'), 'EA', sep='', end='')
print(' $', format(sum_show,'7,d'), sep='')
print('The program has calculated', case_number + 1, 'cases.')- 알고리즘 설명
물품의 이름 관리 같은 부수적인 부분을 제외하고 살펴보면 알고리즘은 이렇다.
모든 물품의 구매 개수가 0으로 초기화된 리스트와 예산 잔액이 담긴 리스트가 있다.
- 현재 수정 중인 위치를 의미하는 노드를 사용
- 기본 노드는 마지막 항목 바로 앞의 항목 (마지막 항목의 수량은 다른 항목에 대한 돈에 의해 결정되어서 일일히 확인할 필요가 없다.)
- 해당 노드의 수량을 하나씩 증가
- 현재 노드에서 예산 내에서 수량을 늘릴 수 없는 경우(예산부족) 노드의 수량을 0으로 초기화하고 노드를 앞으로 이동
- 상위 노드의 수량을 하나 더 추가 후 오류가 발생하는지 확인합니다(오류는 예산 초과, 다른 노드를 변경하는 것 외에 다른 방법이 없음을 의미합니다).
- 오류가 발생하면 현재를 0으로 초기화하고 다시 노드를 올립니다.
- 오류가 없으면 노드를 기본값으로 이동합니다. 첫 번째 노드에서 오류가 발생할 때까지 이 작업을 반복합니다.
여기에서 휴리스틱을 사용했는데, 가격이 비싼 물건을 앞쪽에 놓고 가장 싼 물건을 제일 뒤에 놓으면 마지막 최저가 물품은 나눗셈으로 수량이 결정되어 계산 속도가 향상된다. 가장 싼 물건을 앞쪽 노드에 두면 계산해야 하는 경우의 수가 많아져 퀵소트로 내림차순 정렬하여 계산하였다.
그리고 스택이나 재귀를 사용하지 않고 반복문으로 경우의 수를 계산하였다.
실행 결과는 다음과 같다.
__Generated_Data__
______________________________________________
item # 01 Clean Code $ 26,400
item # 02 진짜 챗GPT $ 14,400
item # 03 OpenCV 4로 $ 29,400
item # 04 리액트 with $ 27,000
item # 05 모두의 깃 $ 14,000
item # 06 실전! 텐서플로 2 $ 25,200
item # 07 비전공자도 이해하는 AI $ 17,820
item # 08 진짜 챗GPT API $ 25,200
item # 09 opencv-python으로 배우는 $ 35,000
item # 10 컴퓨터비전과 딥러닝 $ 39,000
item # 11 HTML + CSS + 자바 $ 24,300
item # 12 허스키렌즈 $ 19,000
______________________________________________
____Sorted_Data____
______________________________________________
item # 01 컴퓨터비전과 딥러닝 $ 39,000
item # 02 opencv-python으로 배우는 $ 35,000
item # 03 OpenCV 4로 $ 29,400
item # 04 리액트 with $ 27,000
item # 05 Clean Code $ 26,400
item # 06 실전! 텐서플로 2 $ 25,200
item # 07 진짜 챗GPT API $ 25,200
item # 08 HTML + CSS + 자바 $ 24,300
item # 09 허스키렌즈 $ 19,000
item # 10 비전공자도 이해하는 AI $ 17,820
item # 11 진짜 챗GPT $ 14,400
item # 12 모두의 깃 $ 14,000
______________________________________________
FOUND 8 PERFECT cases to spend $100,000
#01 #02 #03 #04 #05 #06 #07 #08 #09 #10 #11 #12
0EA 0EA 0EA 0EA 0EA 0EA 0EA 0EA 0EA 0EA 5EA 2EA $100,000
0EA 0EA 0EA 1EA 0EA 0EA 1EA 0EA 1EA 0EA 2EA 0EA $100,000
0EA 0EA 0EA 1EA 0EA 1EA 0EA 0EA 1EA 0EA 2EA 0EA $100,000
0EA 0EA 0EA 3EA 0EA 0EA 0EA 0EA 1EA 0EA 0EA 0EA $100,000
0EA 0EA 1EA 0EA 1EA 0EA 1EA 0EA 1EA 0EA 0EA 0EA $100,000
0EA 0EA 1EA 0EA 1EA 1EA 0EA 0EA 1EA 0EA 0EA 0EA $100,000
0EA 1EA 0EA 1EA 0EA 0EA 0EA 0EA 2EA 0EA 0EA 0EA $100,000
1EA 0EA 0EA 0EA 0EA 0EA 0EA 0EA 1EA 0EA 0EA 3EA $100,000
The program has calculated 2210 cases.관련된 문제
이상하게 백트래킹을 안 써도 풀리는 문제가 많았다.
# 14889번 스타트와 링크
14889번: 스타트와 링크
예제 2의 경우에 (1, 3, 6), (2, 4, 5)로 팀을 나누면 되고, 예제 3의 경우에는 (1, 2, 4, 5), (3, 6, 7, 8)로 팀을 나누면 된다.
www.acmicpc.net






코드 1: 조합을 이용한 브루트 포스
- 접근 방식: itertools.combinations을 사용하여 가능한 모든 팀 조합을 생성하고, 각 조합에 대해 능력치를 계산하여 최소 차이를 찾습니다.
- 시간 복잡도: 이 방식은 모든 가능한 팀 조합을 검토하기 때문에 시간 복잡도가 매우 높습니다. 특히, n이 커질수록 조합의 수는 기하급수적으로 증가합니다. 따라서 실행 시간이 가장 길게 나온 것입니다.
from itertools import combinations
from sys import stdin as si
n = int(si.readline())
stat = [list(map(int,line.split())) for line in si.readlines()]
# 팀 능력치 계산 함수
def calc_stat(team):
return sum(stat[i][j] for i in team for j in team if i != j)
# 최소 차이 계산
min_diff = float('inf')
for team1 in combinations(range(n), n // 2):
team2 = [x for x in range(n) if x not in team1]
diff = abs(calc_stat(team1) - calc_stat(team2))
min_diff = min(min_diff, diff)
print(min_diff)문제의 의도와는 다르게, 라이브러리를 쓰면 하나의 팀을 조합하고 나머지 팀을 조합한 뒤 계산해서 일일히 최소 차이값과 비교할 수 있다. 하지만 이건 백트래킹이 아니다. 2780ms 가 걸렸다.
백트래킹을 하려면 조합 라이브러리를 빼고 탐색을 하다가 조합이 완성되기 전에 가지치기를 해야 한다.
코드 2: 재귀를 이용한 분할 정복
- 접근 방식: 모든 선수를 순회하면서, 각 단계에서 선수를 팀 1 또는 팀 2에 배정하는 재귀적 방식을 사용합니다. 이는 모든 가능한 팀 분할을 검토하지만, 조합을 명시적으로 생성하는 대신 재귀 호출을 통해 구현합니다.
- 시간 복잡도: 코드 1보다는 조금 더 효율적일 수 있으나, 여전히 모든 가능한 분할을 검토하기 때문에 시간 복잡도는 높습니다. 그러나 재귀 호출의 특성 상 일부 중복 계산을 피할 수 있어 코드 1보다 빠릅니다.
from sys import stdin as si
n = int(si.readline())
stat = [list(map(int, line.split())) for line in si.readlines()]
def div_tm(stat, idx, t1, t2, min_diff):
if idx == n: # 모든 선수가 팀에 배정됨
s1 = sum(stat[i][j] for i in t1 for j in t1 if i != j)
s2 = sum(stat[i][j] for i in t2 for j in t2 if i != j)
return min(abs(s1 - s2), min_diff)
if len(t1) < n // 2:
min_diff = min(min_diff, div_tm(stat, idx + 1, t1 + [idx], t2, min_diff))
if len(t2) < n // 2:
min_diff = min(min_diff, div_tm(stat, idx + 1, t1, t2 + [idx], min_diff))
return min_diff
print(div_tm(stat, 0, [], [], float('inf')))div_tm 함수는 재귀적으로 팀을 나누는 모든 경우를 탐색하면서, 각 경우에 대해 두 팀의 능력치 차이를 계산한다. 이때, idx 변수를 사용하여 모든 선수가 팀에 배정될 때까지 과정을 탐색하고, t1과 t2 리스트로 현재까지의 배정을 관리한다. 만약 한 팀의 선수 수가 전체 선수 수의 절반에 도달하지 않았다면, 해당 선수를 해당 팀에 추가하고 다음 선수로 넘어가는 재귀 호출을 수행한다.
백트래킹이 적용되는 부분은, 특정 선수를 팀 1에 배정한 다음(t1 + [idx]를 통해), 그 결과로 나온 최소 능력치 차이와 이전까지의 최소 능력치 차이(min_diff)를 비교하여 업데이트하는 과정과, 팀 1에 배정하지 않고 팀 2에 배정하는 경우(t2 + [idx]를 통해)를 모두 탐색하는 과정에서 나타난다. 모든 가능한 경우의 수를 탐색하지만, 불필요한 경우의 수를 줄이기 위해 현재까지의 최소 차이(min_diff)보다 크다면 더 이상 탐색하지 않고 돌아서는 가지치기(pruning) 기법을 사용하고 있다.
그 결과 2468ms 가 걸렸다.
코드 3: 최적화된 재귀와 전역 변수 사용
- 접근 방식: 코드 2와 유사하지만, 각 재귀 호출에서 현재까지의 능력치 합을 인자로 전달하여 불필요한 계산을 줄입니다. 또한, 전역 변수를 사용하여 최소 차이를 갱신합니다.
- 시간 복잡도: 이 방식은 중간 결과를 재활용하고, 불필요한 계산을 줄여 실행 시간을 크게 단축합니다. 각 재귀 단계에서 능력치의 합을 계산하는 방식이 효율적이어서 더 빠른 실행 시간을 달성합니다.
from sys import stdin as si
n = int(si.readline())
stat = [list(map(int, line.split())) for line in si.readlines()]
min_diff = float('inf')
def div_tm(idx, team1, team2, score1, score2):
global min_diff, n, stat
if idx == n:
min_diff = min(min_diff, abs(score1 - score2))
return
if len(team1) < n // 2:
new_score1 = score1 + sum(stat[idx][i] + stat[i][idx] for i in team1)
div_tm(idx + 1, team1 + [idx], team2, new_score1, score2) # 함수 이름 수정
if len(team2) < n // 2:
new_score2 = score2 + sum(stat[idx][i] + stat[i][idx] for i in team2)
div_tm(idx + 1, team1, team2 + [idx], score1, new_score2) # 함수 이름 수정
div_tm(0, [], [], 0, 0) # 함수 호출 시 stat 인자 제거
print(min_diff)
코드 4: 성능 최적화와 효율적인 재귀 호출
- 접근 방식: 코드 3을 더 발전시켜, 각 선수를 팀에 추가할 때 능력치 변화를 즉시 계산하여 인자로 전달합니다. 이는 능력치 계산을 최소화하고, 불필요한 중복 계산을 제거합니다.
- 시간 복잡도: 각 단계에서의 능력치 계산 최적화로 인해, 이 방식은 모든 코드 중 가장 실행 시간이 짧습니다. 재귀 호출이 효율적으로 관리되며, 각 단계에서 최소한의 계산만 수행하여 전체적인 성능을 크게 향상시킵니다.
from sys import stdin as si
n = int(si.readline())
stat = [list(map(int, line.split())) for line in si.readlines()]
min_diff = float('inf') # 전역 변수 min_diff 초기화
def div_tm(idx, team1, team2, score1, score2):
global min_diff
if idx == n:
min_diff = min(min_diff, abs(score1 - score2))
return
# 팀1에 선수를 추가하는 경우
if len(team1) < n // 2:
new_score1 = score1
for i in team1:
new_score1 += stat[idx][i] + stat[i][idx] # 선수 추가로 인한 능력치 변화
div_tm(idx + 1, team1 + [idx], team2, new_score1, score2)
# 팀2에 선수를 추가하는 경우
if len(team2) < n // 2:
new_score2 = score2
for i in team2:
new_score2 += stat[idx][i] + stat[i][idx] # 선수 추가로 인한 능력치 변화
div_tm(idx + 1, team1, team2 + [idx], score1, new_score2)
div_tm(0, [], [], 0, 0)
print(min_diff)아예 발상의 전환을 한 코드도 보았다.... 전체 능력치를 측정한 뒤 더해서 절반에 가깝게 만드는 아이디어였다!
from sys import stdin
from itertools import combinations
input = stdin.readline()
N = int(input())
stat = [list(map(int,input().split())) for _ in range(N)]
sum_stat = [sum(i) + sum(j) for i, j in zip(stat, zip(*stat))] # 대각선끼리 합
allstat = sum(sum_stat) // 2 # 모든 값 합의 절반
result = float('inf')
for l in combinations(sum_stat, N//2): # 대각선 합에서 뽑은 2개 중에서
result = min(result, abs(allstat - sum(l))) # 모든 값의 절반 - 그 뽑은 2개 합의 차 = start팀 - link팀
print(result)
N-Queen
N*N의 체스판에 N개의 퀸을 간섭 없이 두는 경우의 수를 구하는 문제
한 줄에 하나씩 밖에는 퀸을 둘 수 없기 때문에 한 줄에 하나씩 놓으면서 아래 줄에 놓을 수 있는 곳이 없으면 전 단계로 돌아가서 수를 물리고 다른 것을 시도하는 백트래킹으로 해결할 수 있다.
N-Queen
| 10 초 | 128 MB | 108878 | 52246 | 33879 | 46.564% |
문제
N-Queen 문제는 크기가 N × N인 체스판 위에 퀸 N개를 서로 공격할 수 없게 놓는 문제이다.
N이 주어졌을 때, 퀸을 놓는 방법의 수를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 N이 주어진다. (1 ≤ N < 15)
출력
첫째 줄에 퀸 N개를 서로 공격할 수 없게 놓는 경우의 수를 출력한다.
예제 입력 1 복사
8
예제 출력 1 복사
92import sys
sys.setrecursionlimit(10000)
def dfs(row):
global count
if row == N-1:
# 마지막 줄에 도달했을 때, 가능한 모든 위치를 카운트에 더함
count += sum(1 for i in range(N) if not (col[i] or diag1[row+i] or diag2[row-i+N-1]))
return
for i in range(N):
if not (col[i] or diag1[row+i] or diag2[row-i+N-1]):
col[i] = diag1[row+i] = diag2[row-i+N-1] = True
dfs(row + 1)
col[i] = diag1[row+i] = diag2[row-i+N-1] = False
N = int(input())
count = 0
col = [False] * N # 열 체크
diag1 = [False] * (2*N-1) # 주 대각선 체크
diag2 = [False] * (2*N-1) # 부 대각선 체크
dfs(0)
print(count)이 코드는 N-Queen 문제를 해결하기 위한 알고리즘을 구현한 것이다. N-Queen 문제는 N×N 크기의 체스판에 N개의 퀸을 서로 공격할 수 없게 배치하는 방법을 찾는 문제다. 여기서 구현된 방법은 깊이 우선 탐색(DFS, Depth-First Search) 알고리즘을 사용한다.
- 먼저, sys.setrecursionlimit(10000)을 통해 파이썬의 기본 재귀 깊이 제한을 늘려, 깊이 우선 탐색 시 깊은 재귀 호출에 대비한다.
- 전역 변수 count는 퀸을 서로 공격할 수 없게 배치하는 방법의 수를 세는 데 사용된다.
- col, diag1, diag2 배열은 체스판의 열과 대각선에 퀸이 배치되었는지 여부를 추적한다. 이를 통해 퀸들이 서로 공격할 수 없는 조건을 유지한다.
- col 배열은 각 열에 퀸이 있는지를 나타낸다.
- diag1 배열은 주 대각선에 퀸이 있는지를 나타낸다. 주 대각선은 왼쪽 위에서 오른쪽 아래로 내려가는 대각선이다.
- diag2 배열은 부 대각선에 퀸이 있는지를 나타낸다. 부 대각선은 오른쪽 위에서 왼쪽 아래로 내려가는 대각선이다.
- dfs 함수는 깊이 우선 탐색을 수행한다. 함수는 현재 행 row를 인자로 받아, 해당 행의 모든 열에 대해 퀸을 배치해 본다.
- 만약 현재 행이 마지막 행(N-1)에 도달했다면, 그 행에 배치할 수 있는 모든 가능한 위치의 수를 count에 더한다.
- 각 열에 대해 퀸을 배치할 때, 해당 열과 대각선에 다른 퀸이 없는지 확인한다. 조건을 만족하면 퀸을 배치하고(col, diag1, diag2를 True로 설정), 다음 행으로 넘어간다. 이후, 백트래킹을 통해 다른 가능성을 탐색하기 위해 퀸을 제거한다(col, diag1, diag2를 False로 재설정).
- 사용자로부터 체스판의 크기 N을 입력받아, dfs(0)을 호출함으로써 깊이 우선 탐색을 시작한다. 탐색이 끝나면 count에 저장된 결과를 출력하여, 퀸을 서로 공격할 수 없게 배치하는 방법의 수를 나타낸다.
이 알고리즘은 N-Queen 문제의 해를 찾기 위해 체스판의 모든 가능한 배치를 탐색한다. 따라서, N의 값이 커질수록 계산 시간이 기하급수적으로 증가한다는 점을 유의해야 한다.
이 코드에서 백트래킹은 깊이 우선 탐색(DFS)을 수행하면서, 퀸을 배치할 수 있는 모든 가능한 경우의 수를 탐색하는 과정에서 사용된다. 백트래킹은 해결책으로 이어지지 않는 경로를 발견했을 때, 이전의 분기점으로 돌아가 다른 가능한 경로를 탐색하는 방법이다. 이 과정을 통해 모든 가능한 경우의 수를 효율적으로 탐색한다.
1. 퀸 배치 시도: 알고리즘은 체스판의 각 행에 대해 퀸을 하나씩 배치해본다. 현재 행에서 퀸을 배치할 수 있는 모든 열을 확인한다. 배치가 가능한지 여부는 해당 열과 두 대각선(`diag1`, `diag2`)에 다른 퀸이 없는지를 통해 판단한다.
2. 백트래킹 적용: 특정 위치에 퀸을 배치한 후, 다음 행으로 넘어가서 또 다시 퀸을 배치하는 시도를 한다. 이때 만약 다음 행에서 어떠한 열에도 퀸을 배치할 수 없는 상황이 발생하면, 이는 현재 경로가 해결책으로 이어지지 않음을 의미한다. 따라서, 알고리즘은 이전 행으로 돌아가(백트래킹), 다른 열에 퀸을 배치하는 것을 시도한다.
3. 상태 복원: 퀸을 다른 위치에 배치하기 전에, 이전에 변경했던 상태(`col`, `diag1`, `diag2` 배열에서의 값을)를 원래대로 되돌린다. 이는 다른 모든 가능한 경로를 정확하게 탐색하기 위해 필수적이다. 즉, 퀸을 배치하고 나서 다음 행으로 넘어갔다가 다시 돌아올 때, 원래의 체스판 상태로 복원하여 다른 가능성을 시도할 수 있도록 한다.
이러한 백트래킹 과정을 통해, N-Queen 문제의 모든 해를 효율적으로 찾아낼 수 있다. 코드의 실행 과정에서 백트래킹은 자동적으로 수행되며, 이는 재귀 함수 호출의 형태로 구현된다. 특정 조건에서 재귀 호출을 중단하고 이전 상태로 돌아가는 것이 바로 백트래킹의 핵심이다.


마르코프 결정 과정 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 마르코프 결정 과정(MDP, Markov Decision Process)는 의사결정 과정을 모델링하는 수학적인 틀을 제공한다. 이 때 의사결정의 결과는 의사결정자의 결정에도 좌우되지
ko.wikipedia.org
'Tech > Coding' 카테고리의 다른 글
| # 9251번 LCS (0) | 2024.02.19 |
|---|---|
| # 12865 평범한 배낭(Python 파이썬) (0) | 2024.02.17 |
| 프로필 마크다운 (0) | 2024.02.10 |
| 14889번 스타트와 링크 - 백 트래킹 (0) | 2024.02.08 |
| 백준 # 31287번 장난감 강아지 - 파이썬 (1) | 2024.02.05 |



