

시간 초과가 나서 파이파이로 돌렸더니 틀렸대서 살펴보니 dp탐색 범위가 틀렸음^^;;(마지막 행과 열을 빠뜨림)
dp로 풀기 위해 대조 테이블을 만들었다.
이전까지 연속적으로 같은 개수를 활용하기 위해 패딩으로 0을 좌측과 상단열에 붙였다.


시작 위치 배열은
[(1, 16), (1, 15), (1, 14), (1, 13), (1, 12), (1, 11), (1, 10), (1, 9), (1, 8), (1, 7), (1, 6), (1, 5), (1, 4), (1, 3), (1, 2), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1)]
[(0,y) for y in range(len(string_2)-1,0,-1)] + [(x,0) for x in range(len(string_1)]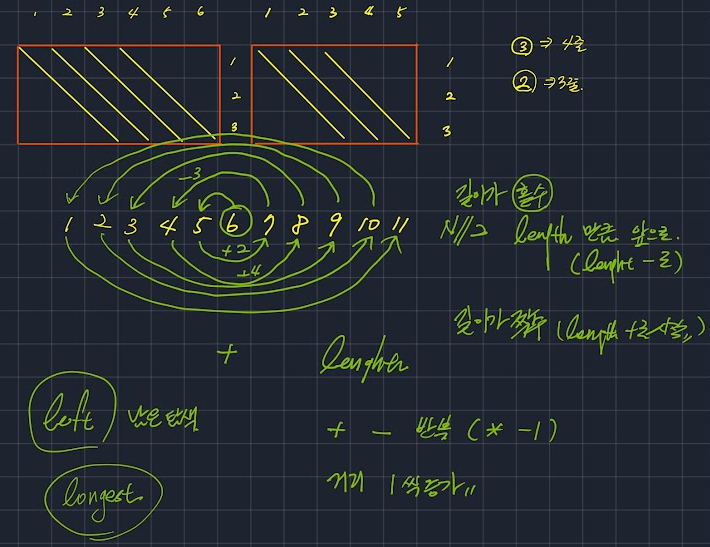
각 줄의 길이(이동 가능 횟수)는 $min(M-x, N-y)$
탐색 순서는 시작위치 26개 중에서 13번째인 (0,3)부터.
이렇게 순회하는 이유는 가장 긴 공통 부분 문자열이 등장할 확률이 가장 높은 구간이기 때문이다.
arr = [1,2,3,4,5,6,7,8,9]
n =len(arr)
index=n//2-1 if n%2==0 else n//2
direction = 1 if n%2==0 else -1
for i in range(1,n+1):
print(arr[index],end=" ")
index+=direction * i
direction *= -1
print()
print(*arr)위 순회 순서 코드처럼 중심으로부터 소용돌이 치며 방문하며
발견된 최대 길이에 따라 각 줄의 남은 길이로 경신이 불가능하면 다음 시작 위치로.
한 줄을 시작하기 전에 순회할 줄의 길이가 최대 길이와 같거나 짧으면 탐색을 종료.
from sys import stdin
def input(): return stdin.readline().rstrip()
s1 = input()
s2 = input()
x_n = len(s1)
y_n = len(s2)
dp = [[0] * (x_n + 1) for _ in range(y_n + 1)]
starts = [(1, y + 1) for y in range(y_n - 1, 0, -1)] + [(x + 1, 1) for x in range(x_n)]
n = len(starts)
index = n // 2 - 1 if n % 2 == 0 else n // 2
direction = 1 if n % 2 == 0 else -1
longest = 0
for i in range(1, n + 1):
x, y = starts[index]
while x <= x_n and y <= y_n:
remained = min(x_n - x, y_n - y)
if s1[x - 1] == s2[y - 1]:
dp[y][x] = dp[y - 1][x - 1] + 1
longest = max(longest, dp[y][x])
elif remained <= longest:
break
x += 1
y += 1
index += direction * i
direction *= -1
print(longest)파이파이로 겨우 통과했다.
1등 코드를 살펴보니 Manber-Myers 알고리즘을 사용한 것 같다.
https://ko.wikipedia.org/wiki/%EC%A0%91%EB%AF%B8%EC%82%AC_%EB%B0%B0%EC%97%B4
접미사 배열 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 컴퓨터 과학에서 접미사 배열이란 어떤 문자열의 접미사를 사전식 순서대로 나열한 배열을 말한다. 문자열 검색이나 전문 검사 등에 쓰인다. 영어로는 suffix arr
ko.wikipedia.org
# line1029님 코드입니다.
# Manber-Myers Algorithm
from sys import stdin, stdout
a, b = stdin.read().splitlines()
s = a + "$" + b
n = len(s)
a = len(a)
suffix_array = list(range(n))
rank_arr = [ord(s[i]) - 65 for i in range(n)]
rank_arr.append(-1)
tmp_arr = [0]*(n + 1)
tmp_arr[-1] = -1
p = 1
while p < n:
# sort suffix array by given rank
suffix_array.sort(key=lambda x: (rank_arr[x], rank_arr[min(x + p, n)]))
# make next rank based on prev rank
for i in range(n - 1):
x, y = suffix_array[i], suffix_array[i + 1]
if rank_arr[x] != rank_arr[y] or rank_arr[x + p] != rank_arr[y + p]:
tmp_arr[y] = tmp_arr[x] + 1
else:
tmp_arr[y] = tmp_arr[x]
p <<= 1
rank_arr = tmp_arr[:]
if rank_arr[suffix_array[n - 1]] == n - 1:
break
offset = 0
lcp = [0]*n
for i, x in enumerate(rank_arr):
if x > 0:
prev = suffix_array[x - 1]
while max(prev, i) + offset < n and s[prev + offset] == s[i + offset]:
offset += 1
lcp[x] = offset
offset = max(0, offset - 1)
length = -1
for i, j in enumerate(lcp):
if suffix_array[i - 1] + j - 1 < a and a < suffix_array[i] + j - 1 < n and j > length:
length = j
if suffix_array[i] + j - 1 < a and a < suffix_array[i - 1] + j - 1 < n and j > length:
length = j
stdout.write(str(length))
접미사 배열 이해하기
접미사 배열은 문자열 처리에서 중요한 자료구조입니다. 문자열의 모든 접미사를 사전순으로 나열한 배열입니다. 쉽게 말해, 특정 문자열 뒤에 오는 모든 부분 문자열을 모아 놓은 곳이라고 생각하면 됩니다.
예시:
문자열 "banana"를 생각해 보세요. 이 문자열의 모든 접미사는 다음과 같습니다.
- “” (빈 문자열)
- “a”
- “na”
- “ana”
- “banana”
이 접미사들을 사전순으로 정렬하면 다음과 같습니다.
- “”
- “a”
- “ana”
- “banana”
- “na”
코드:
다음은 Python 코드로 접미사 배열을 만드는 방법입니다.
Python
def create_suffix_array(s):
n = len(s)
suffix_array = [(s[i:], i) for i in range(n)]
suffix_array.sort()
return [i for i, _ in suffix_array]
# 예시 실행
text = "banana"
suffix_array = create_suffix_array(text)
print(suffix_array) # 결과: [0, 3, 1, 4, 2]
활용:
접미사 배열은 다양한 문자열 처리 작업에 활용됩니다. 몇 가지 예시를 살펴보겠습니다.
- 문자열 검색: 특정 문자열이 주어진 텍스트에 포함되어 있는지 빠르게 확인할 수 있습니다.
- 부분 문자열 검색: 주어진 텍스트에서 특정 패턴과 일치하는 모든 부분 문자열을 찾을 수 있습니다.
- 문자열 비교: 두 문자열이 얼마나 유사한지 비교하는 데 사용할 수 있습니다.
- 텍스트 압축: 반복되는 문자열 패턴을 식별하여 압축에 활용할 수 있습니다.
장점:
- 접미사 배열은 문자열 검색 및 기타 작업에 매우 빠른 속도를 제공합니다.
- 비교적 적은 메모리를 사용합니다.
- 다양한 문자열 처리 작업에 활용 가능합니다.
단점:
- 공간 복잡도가 O(n)입니다 (n은 문자열 길이).
- 만드는 데 O(n log n) 시간이 소요됩니다.
더 알아보기:
- https://en.wikipedia.org/wiki/Suffix_array
- https://www.geeksforgeeks.org/suffix-arrays-for-competitive-programming/
Suffix Arrays for Competitive Programming - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
SA-IS 알고리즘
SA-IS 알고리즘은 접미사 배열(suffix array)을 구축하기 위한 효율적인 알고리즘 중 하나입니다. 이 알고리즘은 인버스 서브 문제(inverse subproblem)를 풀고, 그것을 통해 원래의 문제를 해결합니다.
알고리즘 단계
- 인버스 서브 문제 풀기: 입력 문자열을 미리 정의된 길이의 버킷(bucket)으로 분할합니다. 이를 통해 버킷 내에서 접미사들의 순서를 결정할 수 있습니다.
- 재귀적으로 버킷 정렬: 인버스 서브 문제의 해결을 바탕으로 재귀적으로 각 버킷을 정렬합니다.
- L 형과 S 형 정렬: 버킷의 정렬을 바탕으로 각 접미사를 L 형과 S 형으로 분류합니다(L 형: 사전순으로 이전 접미사보다 큰 것, S 형: 그 외).
- 임의적으로 분류된 접미사 정렬: L 형과 S 형으로 분류된 접미사를 조합하여 정렬합니다.
- LMS(Least Significant) 접미사들의 정렬: L 형과 S 형으로 분류된 LMS 접미사들을 정렬합니다.
- LMS 접미사들의 이름 붙이기: LMS 접미사들에 이름을 붙입니다.
- LMS 접미사들의 정렬: LMS 접미사들을 기반으로 전체 접미사를 정렬합니다.
- LMS 접미사들의 등급 부여: LMS 접미사들을 등급을 부여하여 정렬합니다.
- 중복 제거: 중복된 LMS 접미사를 제거합니다.
- 새로운 입력 생성: 중복 제거된 LMS 접미사를 바탕으로 새로운 입력을 생성합니다.
- 재귀적으로 접미사 배열 계산: 새로운 입력을 바탕으로 재귀적으로 접미사 배열을 계산합니다.
코드 예시
def sa_is(s):
# 인버스 서브 문제 풀기
buckets = get_buckets(s)
# 재귀적으로 버킷 정렬
sorted_buckets = recursive_bucket_sort(s, buckets)
# L 형과 S 형 정렬
types = classify_types(s, sorted_buckets)
# 임의적으로 분류된 접미사 정렬
sorted_suffixes = sort_suffixes(s, sorted_buckets, types)
# LMS 접미사들의 정렬
lms_suffixes = get_lms_suffixes(sorted_suffixes, types)
sorted_lms_suffixes = sort_lms_suffixes(s, lms_suffixes)
# LMS 접미사들의 이름 붙이기
lms_names = label_lms_suffixes(sorted_lms_suffixes)
# LMS 접미사들의 정렬
sorted_lms_suffixes = sort_suffixes(s, sorted_buckets, types, lms_names)
# LMS 접미사들의 등급 부여
ranks = assign_ranks(sorted_lms_suffixes)
# 중복 제거
unique_lms_suffixes = remove_duplicates(sorted_lms_suffixes)
# 새로운 입력 생성
new_input = induce_new_input(unique_lms_suffixes)
# 재귀적으로 접미사 배열 계산
if len(unique_lms_suffixes) == len(new_input):
return unique_lms_suffixes
else:
sa = sa_is(new_input)
return induce_sa_from_lms(sa, ranks, types)
Manber-Myers 알고리즘
Manber-Myers 알고리즘은 문자열 매칭 문제를 해결하는 데 사용되는 효율적인 알고리즘 중 하나입니다. 이 알고리즘은 텍스트를 사전에 정렬된 접미사 배열(suffix array)로 변환한 다음, 효율적으로 패턴을 찾아냅니다.
알고리즘 단계
- 접미사 배열 생성: 입력 텍스트의 접미사 배열을 생성합니다.
- 이진 탐색: 이진 탐색을 사용하여 접미사 배열에서 패턴과 일치하는 접미사를 찾습니다.
- 접미사 비교: 이진 탐색을 통해 찾은 접미사와 패턴을 비교하여 일치하는 부분을 찾습니다.
- 모든 접미사 검사: 접미사 배열에서 모든 접미사를 검사하여 패턴과 일치하는 부분을 찾습니다.
코드 예시
def manber_myers(text, pattern):
suffix_array = generate_suffix_array(text)
occurrences = []
# 이진 탐색을 사용하여 패턴과 일치하는 접미사를 찾음
left = 0
right = len(suffix_array) - 1
while left <= right:
mid = (left + right) // 2
suffix = suffix_array[mid]
if pattern == text[suffix:suffix+len(pattern)]:
occurrences.append(suffix)
break
elif pattern < text[suffix:]:
right = mid - 1
else:
left = mid + 1
# 패턴과 일치하는 접미사를 찾은 후 접미사 비교하여 모든 일치하는 위치 찾음
for i in range(mid+1, len(suffix_array)):
suffix = suffix_array[i]
if pattern == text[suffix:suffix+len(pattern)]:
occurrences.append(suffix)
else:
break
return occurrences
결론
SA-IS 알고리즘은 접미사 배열을 효율적으로 구축하는 데 사용되고, Manber-Myers 알고리즘은 문자열 매칭 문제를 해결하는 데 효과적